scrapy进阶
全站数据爬取
将网站中某板块下的全部页码对应页面数据进行爬取
实现方式
将所有页面url添加到start_urls列表
手动进行请求发送
import scrapy
from story_spider.items import StorySpiderItem
# 必须继承scrapy.Spider
class StoryxcSpider(scrapy.Spider):
# 爬虫文件的名称:爬虫源文件的一个唯一标识
name = 'storyxc'
# 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
# allowed_domains = ['storyxc.com']
# 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.521609.com/meinvxiaohua/']
url_template = 'http://www.521609.com/meinvxiaohua/list12%d.html'
page_num = 2
def parse(self, response):
li_list = response.xpath('//div[@id="content"]/div[2]/div[2]/ul/li')
for li in li_list:
img_name = li.xpath('./a[2]//text()').extract_first()
print(img_name)
if self.page_num <= 11:
next_url = format(self.url_template % self.page_num)
self.page_num += 1
# 手动请求发送:yield scrapy.Request(url,callback)
# callback专门用作数据解析
yield scrapy.Request(url=next_url, callback=self.parse)五大核心组件
- 引擎
- 调度器
- 下载器
- Spider
- 管道
流程:
spider中产生url,对url进行请求发送
url会被封装成请求对象交给引擎,引擎把请求给调度器
调度器会使用过滤器将引擎提交的请求去重,将去重后的请求对象放入队列
调度器会把请求对象从队列中调度给引擎,引擎把请求交给下载器
下载器去互联网中进行数据下载,将数据封装在response里返回给引擎
引擎将response返回给spider,spider对数据进行解析,将数据封装到item当中,交给引擎
引擎把item交给管道
管道进行持久化存储
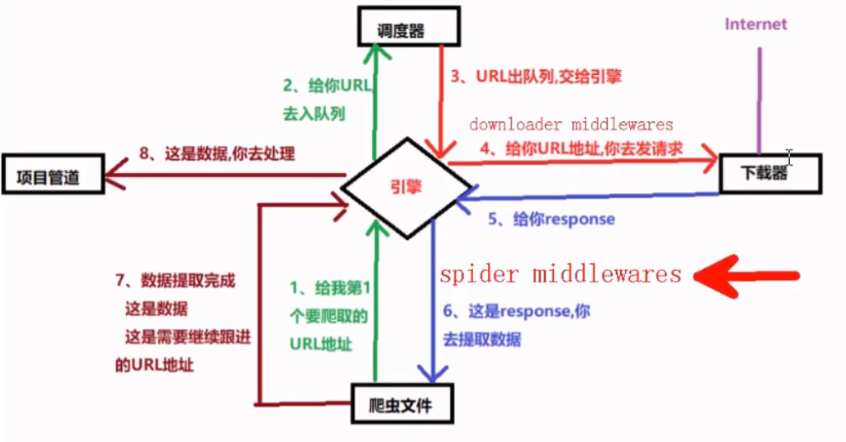
请求传参
使用场景:如果爬取解析的数据不再同一张页面中(深度爬取)
yield scrapy.Request(url,callback,meta= {'item':item})- 请求传参 item可以传递给callback回调函数
图片爬取之ImagePipeline
- 字符串持久化:xpath解析交给管道持久化
- 图片持久化:xpath解析出src属性,单独对图片地址发起请求获取图片二进制类型数据
ImagePipeline
只需要解析出img的src属性进行解析并提交到管道,管道就会对图片的src进行请求发送获取二进制数据
爬虫文件
import scrapy
from story_spider.items import StorySpiderItem
# 必须继承scrapy.Spider
class StoryxcSpider(scrapy.Spider):
# 爬虫文件的名称:爬虫源文件的一个唯一标识
name = 'storyxc'
# 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
# allowed_domains = ['storyxc.com']
# 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://sc.chinaz.com/tupian/']
def parse(self, response):
div_list = response.xpath('//div[@id="container"]/div')
for div in div_list:
# 该网站有懒加载,要使用伪属性
src = div.xpath('./div/a/img/@src2').extract_first()
real_src = 'https:' + src
# print(real_src)
item = StorySpiderItem()
item['src'] = real_src
yield itemItems
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class StorySpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field()Pipeline
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class ImagePipeline(ImagesPipeline):
# 根据图片地址进行图片数据的请求
def get_media_requests(self, item, info):
print(item['src'])
yield scrapy.Request(item['src'])
def file_path(self, request, response=None, info=None, *, item=None):
# 指定图片存储路径
imageName = request.url.split('/')[-1]
return imageName
def item_completed(self, results, item, info):
return item # 返回给下一个被执行的管道类settings
# 保存的文件夹
IMAGES_STORE = './imgs'
# 启用管道
ITEM_PIPELINES = {
# 300表示优先级,数值越小,优先级越高
'story_spider.pipelines.ImagePipeline': 300
}DANGER
这里直接运行不会报错,但是会发现也没有下载成功,但是实际上url已经能拿到了,把日志的级别放开后,查看日志信息会发现有一句 2021-05-01 13:22:48 [scrapy.middleware] WARNING: Disabled ImgsPipeline: ImagesPipeline requires installing Pillow 4.0.0 or later
提示使用ImagesPipeline还需要安装下pillow :pip install pillow
这个很坑,不仔细看找不到,排查了半天才解决
安装完pillow后启动爬虫,可以看到图片已经下载完成
中间件
- 下载中间件
- 位置:引擎和下载器之间
- 作用:批量拦截到整个工程中所有的请求和响应
- 拦截请求:
- UA伪装
- 代理IP设置
- 拦截响应:
- 篡改响应数据,响应对象
- 核心方法:
- process_request:拦截请求
- process_response:拦截响应
- processs_exception:拦截发生异常的请求
- 爬虫中间件
- 位置:在引擎及爬虫
- 作用:处理spider的输入(response)和输出(item及requests).
下载中间件
def process_request(self, request, spider):
# UA 伪装,也可以设置ua池,随机设置
request.headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
# 设置代理
request.meta['proxy'] = 'https://ip:port'
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# 发生异常的请求切换代理 也可以实现代理池,指定切换逻辑
request.meta['proxy'] = 'https://ip:port'
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
return request #将修正后的request重新进行发送案例:爬取网易新闻指定分类下的新闻标题和内容
爬虫类
import scrapy
from story_spider.items import StorySpiderItem
# 必须继承scrapy.Spider
class StoryxcSpider(scrapy.Spider):
# 爬虫文件的名称:爬虫源文件的一个唯一标识
name = 'storyxc'
# 允许的域名:用来限定start_urls列表中哪些url可以进行请求发送
# allowed_domains = ['storyxc.com']
# 起始的url列表,该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['https://news.163.com/']
module_urls = []
def __init__(self):
super().__init__(self)
from selenium import webdriver
self.browser = webdriver.Chrome()
def parse(self, response):
li_list = response.xpath('//*[@id="index2016_wrap"]/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li')
need_index = [3, 4, 6]
for index in need_index:
module_url = li_list[index].xpath('./a/@href').extract_first()
self.module_urls.append(module_url)
for url in self.module_urls:
yield scrapy.Request(url, callback=self.parse_module)
# 解析篡改过的 已经添加了动态加载数据的响应信息
def parse_module(self, response):
div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div[1]/div/ul/li/div/div')
for div in div_list:
# news_title = div.xpath('./div/div[1]/h3/a/text()').extract_first()
detail_url = div.xpath('./div/div[1]/h3/a/@href').extract_first()
yield scrapy.Request(url=detail_url,callback=self.parse_detail)
# 解析新闻详情页
def parse_detail(self, response):
title = response.xpath('//*[@id="container"]/div[1]/h1/text()').extract_first()
detail_text = response.xpath('//*[@id="content"]/div[2]//text()').extract()
detail_text = ''.join(detail_text)
item = StorySpiderItem()
item['title'] = title
item['content'] = detail_text
yield item
def closed(self,spider):
self.browser.quit()中间件类
只展示了下载中间件
class StorySpiderDownloaderMiddleware:
def process_request(self, request, spider):
return None
# 拦截模块对应的响应对象,进行篡改
# 由于是动态加载的内容,使用selenium
def process_response(self, request, response, spider):
# 过滤指定的响应对象
urls = spider.module_urls
bro = spider.browser
from scrapy.http import HtmlResponse
from time import sleep
# 只有指定模块url的数据才使用selenium请求并进行篡改数据
if request.url in urls:
bro.get(request.url) # selenium请求详情页
sleep(3)
page_data = bro.page_source # 包含了动态加载的新闻数据
# 要爬取的指定模块的响应内容
# 实例化一个新的响应对象 (包含动态加载的新闻数据),替代原来的响应对象
new_res = HtmlResponse(url=request.url,body=page_data,encoding='utf-8',request=request)
return new_res
return response
def process_exception(self, request, exception, spider):
return request #将修正后的request重新进行发送Item类
import scrapy
class StorySpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()Pipeline类
class StroyxcPipeline(object):
fp = None
def open_spider(self, spider):
self.fp = open('./163news.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(item['title'] + ':' + item['content'] + '\n')
return item
def close_spider(self, spider):
self.fp.close()settings配置
BOT_NAME = 'story_spider'
SPIDER_MODULES = ['story_spider.spiders']
NEWSPIDER_MODULE = 'story_spider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = {
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'story_spider.middlewares.StorySpiderDownloaderMiddleware': 543,
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 300表示优先级,数值越小,优先级越高
'story_spider.pipelines.StroyxcPipeline': 300
}运行结果:
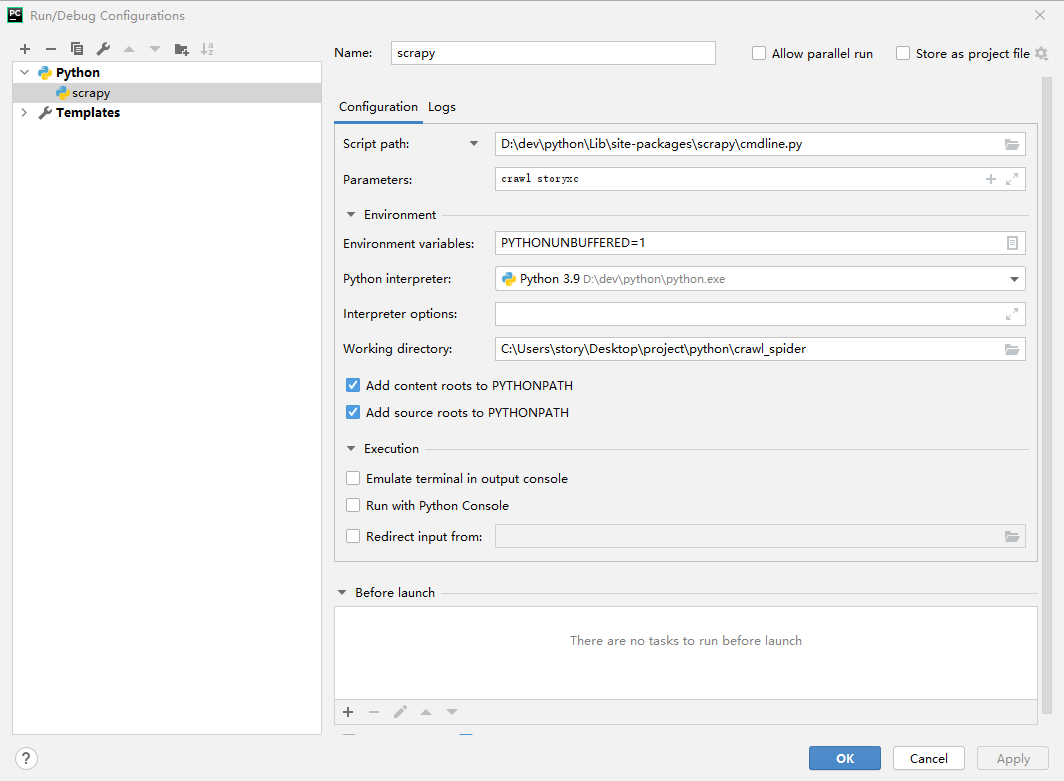
scrapy调试
pycharm中编辑运行/debug配置
点击加号添加一个新的配置,选择python,给配置命个名,比如scrapy
script path选择python目录下的
Lib/site-packages/scrapycmdline.pyparameter填
crawl yourSpiderNameworking directory填写爬虫项目路径
保存,再debug运行scrapy这个配置就行
例如: