python并发编程
python对并发编程的支持
多线程:threading,利用CPU运算和IO可以同时执行,让CPU不会干巴巴等待IO完成
多进程:multiprocessing,利用多核CPU的能力,真正的并行执行任务
异步IO:asyncio,在单线程中利用CPU和IO同时执行的原理,实现函数异步执行
使用Lock对资源加锁,防止冲突访问
使用Queue实现不同线程、进程之间的数据通信,实现生产者消费者模式
使用线程池Pool、进程池Pool,简化线程、进程任务的提交、等待结束、获取结果
使用subprocess启动外部程序的进程,并进行输出交互
如何选择多线程/多进程/多协程
什么是CPU密集型、IO密集型
CPU密集型计算:也叫计算密集型,指I/O很短时间内就完成,CPU需要大量计算和处理,特点是CPU占用率很高,例如解压缩,加密解密,正则匹配等。
I/O密集型计算:硬盘、内存、网络的读写操作,例如文件处理、网络爬虫、读写数据库等。
对比
多进程Process(multiprocessing):
- 优点:可以利用多核CPU进行并行运算
- 缺点:占用资源多,可启动数目少
- 适用于:计算密集型任务,例如解压缩、加解密。。
多线程Thread(threading):
一个进程中可以启动多个线程
相比进程更轻量级,占用资源更少。但只能单CPU并发执行,不能利用多CPU(GIL,全局解释器锁)
相比协程,线程启动数目有限制,占用内存资源,有线程切换的开销
适用于:IO密集型任务,同时运行的任务数目要求不高
多协程Coroutine(asyncio):
一个线程中可以启动多个协程
优点:内存开销最小,启动数量最多
缺点:支持的库有限(aiohttp vs requests),代码实现较为复杂
适用于:I/O密集型任务,需要超多任务运行且有现有库支持的场景
多线程
多线程的两种实现方式
通过threading模块的Thread类
import time
import threading
import requests
import threading
import time
urls = [f'https://www.cnblogs.com/#p{i}' for i in range(1, 50)]
def craw(url):
r = requests.get(url)
time.sleep(1)
print(url, len(r.text))
if __name__ == '__main__':
start = time.time()
t = threading.Thread(target=craw, args=(urls[0],))
t.start()
t.join()
print(f'cost {start - time.time()}s')通过继承Thread类
import requests
import time
import threading
from blog_spider import urls
class MyThread(threading.Thread):
def __init__(self, url):
super().__init__()
self.url = url
def run(self):
r = requests.get(self.url)
time.sleep(1)
print(self.url, len(r.text))
if __name__ == '__main__':
start = time.time()
t = MyThread(urls[0])
t.start()
t.join()
print(time.time() - start)线程同步
使用 Thread 对象的 Lock 实现
import threading
import time
class MyThread(threading.Thread):
def __init__(self, thread_id, name, counter):
super().__init__(name=name)
self.name = name
self.thread_id = thread_id
self.counter = counter
def run(self):
print("开启线程: " + self.name)
# 获取锁.用于线程同步
my_lock.acquire()
print_time(self.name, self.counter, 3)
# 释放锁
my_lock.release()
def print_time(thread_name, delay, counter):
while counter:
time.sleep(delay)
print(f"#{thread_name}: {time.ctime(time.time())}")
counter -= 1
my_lock = threading.Lock()
threads = []
# 创建新线程
thread1 = MyThread(1, "Thread-1", 1)
thread2 = MyThread(2, "Thread-2", 2)
thread1.start()
thread2.start()
# 添加到线程列表
threads.append(thread1)
threads.append(thread2)
for t in threads:
t.join()
print("退出主线程")结果:
开启线程: Thread-1
开启线程: Thread-2
#Thread-1: Mon Apr 12 21:54:42 2021
#Thread-1: Mon Apr 12 21:54:43 2021
#Thread-1: Mon Apr 12 21:54:44 2021
#Thread-2: Mon Apr 12 21:54:46 2021
#Thread-2: Mon Apr 12 21:54:48 2021
#Thread-2: Mon Apr 12 21:54:50 2021
退出主线程Lock的使用方式
1.try-finally模式
import threading
lock = threading.lock()
lock.acquire()
try:
#do something
finally:
lock.release()- with模式
import threading
lock = threading.lock()
with lock:
# do something生产者消费者模型
import requests
from bs4 import BeautifulSoup
urls = [f'https://www.cnblogs.com/#p{i}' for i in range(1, 50)]
def craw(url):
r = requests.get(url)
return r.text
def parse(html):
soup = BeautifulSoup(html, 'html.parser')
links = soup.find_all('a', class_='post-item-title')
return [(link.get('href'), link.get_text()) for link in links]import queue
import threading
import time
import random
import blog_spider
def do_crawl(url_queue: queue.Queue, html_queue: queue.Queue):
while True:
url = url_queue.get()
html = blog_spider.craw(url)
html_queue.put(html)
def do_parse(html_queue: queue.Queue, fout):
while True:
html = html_queue.get()
results = blog_spider.parse(html)
for result in results:
fout.write(str(result) + '\n')
time.sleep(1)
if __name__ == '__main__':
url_queue = queue.Queue()
html_queue = queue.Queue()
for url in blog_spider.urls:
url_queue.put(url)
for i in range(3):
t = threading.Thread(target=do_crawl, args=(url_queue, html_queue), name='crawl-{}'.format(i))
t.start()
fout = open('results.txt', 'w')
for i in range(3):
t = threading.Thread(target=do_parse, args=(html_queue, fout), name='parse-{}'.format(i))
t.start()线程优先级队列实现
import queue
import threading
import time
exitFlag = 0
class MyThread(threading.Thread):
def __init__(self, thread_id, name, q):
super().__init__(name=name)
self.threadId = thread_id
self.name = name
self.q = q
def run(self):
print("开启线程: " + self.name)
process_data(self.name, self.q)
print("退出线程: " + self.name)
def process_data(name, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print(f"{name} processing {data}")
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
queueLock = threading.Lock()
nameList = ["ONE", "TWO", "THREE", "FOUR", "FIVE"]
workQueue = queue.Queue(10)
threads = []
threadId = 1
for tname in threadList:
thread = MyThread(threadId, tname, workQueue)
thread.start()
threads.append(thread)
threadId += 1
queueLock.acquire()
for name in nameList:
workQueue.put(name)
queueLock.release()
while not workQueue.empty():
pass
exitFlag = 1
for t in threads:
t.join()
print("主线程退出")运行结果:
开启线程: Thread-1
开启线程: Thread-2
开启线程: Thread-3
Thread-1 processing ONE
Thread-2 processing TWO
Thread-3 processing THREE
Thread-2 processing FOUR
Thread-1 processing FIVE
退出线程: Thread-2
退出线程: Thread-1
退出线程: Thread-3
主线程退出多线程线程池ThreadPoolExecutor
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
def get_data(times):
time.sleep(times)
print("get data {} success".format(times))
thread_pool = ThreadPoolExecutor(max_workers=2)
task1 = thread_pool.submit(get_data, 3)
task2 = thread_pool.submit(get_data, 2)
datas = [1, 2, 3]
# submit后直接返回
all_tasks = [thread_pool.submit(get_data, data) for data in datas]
# as_complete底层是生成器
# for future in as_completed(all_tasks):
# res = future.result()
# print(res)
for data in thread_pool.map(get_data, datas):
print("get {} data ".format(data))ThreadPoolExecutor提交任务的两种方式
- pool.map(func, params):func为处理函数,params为所有待处理的数据,返回值为按顺序返回。这种方式适合任务数据全部准备好一次提交处理的场景
- future = pool.submit(func,param):func为处理函数,param为待处理的一条数据,返回值为future。这种方式适合一条条数据提交处理的场景。处理多个future集合futures时,可以直接遍历,也可以配合
as_complete使用,这种方式是按任务完成顺序返回。
多进程
对于io操作来说,使用多线程
对于耗cpu的操作,用多进程
- 进程的切换代价高于多线程
from concurrent.futures import ProcessPoolExecutor
import multiprocessing
import time
# 多进程编程
def get_html(n):
time.sleep(n)
return n
if __name__ == '__main__':
# progress = multiprocessing.Process(target=get_html, args=(2,))
# print(progress.pid)
# progress.start()
# print(progress.pid)
# progress.join()
# print('main progress end')
# 使用进程池
pool = multiprocessing.Pool(multiprocessing.cpu_count())
# res = pool.apply_async(get_html, args=(3,))
# 不再接受任务
# pool.close()
# 等待所有任务完成
# pool.join()
# print(res)
# print(res.get())
# imap 按顺序
# for res in pool.imap(get_html, [1, 5, 3]):
# print("{} sleep success".format(res))
# imap_unordered 按完成时间
for res in pool.imap_unordered(get_html, [1, 5, 3]):
print("{} sleep success".format(res))进程间通信
- 使用multiprocessing中的Queue 用法和threading的Queue类似
- 全局共享变量不适用与进程间通信(进程间的数据是隔离的)
- multiprocessing中的Queue不能用于进程池pool中的进程通信
- pool中的进程间通信需要使用multiprocessing中的Manager实例化后的queue(Manager().Queue())
- 使用Pipe管道实现进程间通信 receive,send = Pipe() 只能适用于两个进程间通信
- Manager().dict()等数据结构进行进程间通信

协程
协程,又称微线程,纤程。英文名Coroutine。是一种用户态的上下文切换技术。协程的作用是在执行函数A时可以随时中断去执行函数B,然后中断函数B继续执行函数A(可以自由切换)。但这一过程并不是函数调用,这一整个过程看似像多线程,然而协程只有一个线程执行。
协程的优势
- 效率极高,因为子程序切换不是线程切换,由程序自身控制,没有切换线程的开销,所以与多线程相比,线程的数量越多,协程的性能优势越明显。
- 不需要多线程的同步机制,因为只有一个线程,也不存在同时写变量的线程安全问题,在控制共享资源时也不需要加锁,因此执行效率高很多。
协程可以处理IO密集型程序的效率问题,但是CPU密集型不是它的长处,要充分发挥CPU的利用率可以结合多进程+协程
实现协程的方式:
- yield关键字
- asyncio装饰器
- async、await关键字(推荐)
事件循环
asyncio模块中,每一个进程都有一个事件循环。把一些函数注册到事件循环上,当满足事件发生的时候,调用相应的协程函数
事件循环的作用是管理所有的事件,在整个程序运行过程中不断循环执行,追踪事件发生的顺序将它们放到队列中,当主线程空闲的时候,调用相应的事件处理者处理事件。
伪代码:
任务列表 = [任务1,任务2,任务3...]
while true:
可执行的任务列表,已完成的任务列表 = 检查所有任务,将可执行的和已完成的任务返回
for 就绪任务 in 可执行的任务:
执行就绪任务
for 已完成的任务 in 已完成的任务:
剔除已完成的任务
如果任务列表的全部任务都已完成,终止循环import asyncio
# 生成或获取一个事件循环
loop = asyncio.get_event_loop()
# 将任务放到任务列表
loop.run_until_complete(任务)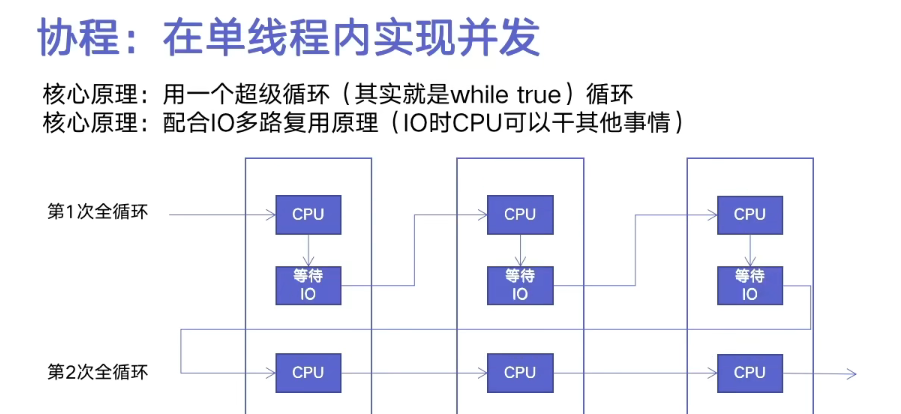
协程函数
定义函数时,如果是async def 函数的函数,就是一个协程函数
协程对象
执行协程函数得到的对象
TIP
执行协程函数创建协程对象,函数内部代码不会立即执行
如果想运行协程函数内部代码,必须将协程对象交给事件循环处理
import asyncio
# 定义一个协程函数
async def func():
print("异步编程")
# 生成一个事件循环
loop = asyncio.get_event_loop()
# 得到协程对象
res = func()
# 将协程对象交给事件循环
loop.run_until_complete(res)
# asyncio.run(res)
res:
异步编程如果不把协程对象放入事件循环
import asyncio
# 定义一个协程函数
async def func():
print("异步编程")
# 生成一个事件循环
loop = asyncio.get_event_loop()
# 得到协程对象
res = func()
res:
sys:1: RuntimeWarning: coroutine 'func' was never awaited异步IO
import asyncio
# 获取事件循环
loop = asyncio.get_event_loop()
# 定义协程函数
async def hello(count):
print(f"Hello World! {count}")
await asyncio.sleep(1)
# 创建task列表
tasks = [loop.create_task(hello(count)) for count in range(10)]
# 执行事件列表
loop.run_until_complete(asyncio.wait(tasks))异步IO爬虫
import asyncio
import aiohttp
import blog_spider
import time
async def async_craw(url):
print('开始爬取:', url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
result = await response.text()
print('爬取结束:', url, len(result))
loop = asyncio.get_event_loop()
tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
print('耗时:', time.time() - start)
---使用信号量控制异步爬虫并发度
sem = asyncio.Semaphore(10)
async with sem:
# work with shared resource
-----------------------------------
sem = asyncio.Semaphore(10)
await sem.acquire()
try:
# work with shared resource
finally:
sem.release()import asyncio
import aiohttp
import blog_spider
sem = asyncio.Semaphore(10)
async def async_craw(url):
print('开始爬取:', url)
async with sem:
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
result = await response.text()
print('爬取结束:', url, len(result))
loop = asyncio.get_event_loop()
tasks = [loop.create_task(async_craw(url)) for url in blog_spider.urls]
import time
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
print('耗时:', time.time() - start)python3.7后的新语法
使用asyncio.run()代替原来创建事件循环,使用事件循环执行函数的操作
import asyncio
import blog_spider
# async def 定义协程函数
async def async_craw(url):
print('开始爬取:', url)
# 触发io操作,调用其他协程
await asyncio.sleep(0)
print('爬取完成:', url)
async def main():
# 创建协程列表
tasks = [async_craw(url) for url in blog_spider.urls]
# asyncio.gather(*task)表示协同执行tasks列表里的所有协程
await asyncio.gather(*tasks)
#
asyncio.run(main())asyncio.wait和asyncio.gather异同
- 相同:从功能上看,
asyncio.wait和asyncio.gather实现的效果是相同的,都是把所有 Task 任务结果收集起来。 - 不同:
asyncio.wait会返回两个值:done和pending,done为已完成的协程Task,pending为超时未完成的协程Task,需通过future.result调用Task的result;而asyncio.gather返回的是所有已完成Task的result,不需要再进行调用或其他操作,就可以得到全部结果。
await关键字
await + 可等待的对象(协程对象、Future对象、Task对象 -> io等待)
import asyncio
async def func():
print('异步编程')
response = await asyncio.sleep(2)
print("结束",response)
asyncio.run(func())示例:
import asyncio
async def others():
print('start')
await asyncio.sleep(2)
print('end')
return '返回值'
async def func():
print('执行协程函数内部代码')
# 遇到IO操作挂起当前协程,等到IO完成后继续运行,当前协程挂起时,事件循环可以执行其他协程
response = await others()
print(f'IO的结果是:{response} ')
asyncio.run(func())
res:
执行协程函数内部代码
start
end
IO的结果是:返回值Task对象
Tasks用于并发调度协程,是对协程对象的一种封装,其中包含了任务的各个状态。通过asyncio.create_task()函数创建Task对象,这样可以让协程加入事件循环中等待调度执行。还可以使用低层级的loop.create_task()或asyncio.ensure_future()函数。不建议手动实例化Task对象。
示例1:
import asyncio
async def func():
print(1)
await asyncio.sleep(2)
print(2)
return '返回值'
async def main():
print('main函数开始')
# 创建task对象,将当前执行func函数的任务添加到事件循环
task1 = asyncio.create_task(func())
task2 = asyncio.create_task(func())
print('main函数结束')
# 当执行某协程遇到IO操作,会自动切换执行其他任务
res1 = await task1
res2 = await task2
print(res1, res2)
asyncio.run(main())
res:
main函数开始
main函数结束
1
1
2
2
返回值 返回值示例2:
import asyncio
async def func():
print(1)
await asyncio.sleep(2)
print(2)
return '返回值'
async def main():
print('main函数开始')
task_list = [
asyncio.create_task(func()),
asyncio.create_task(func())
]
print('main函数结束')
done,pending = await asyncio.wait(task_list,timeout=None)
print(done)
asyncio.run(main())asyncio.Future对象
Task继承了Future,Task对象内部await的结果的处理基于Future对象
async def main():
loop = asyncio.get_running_loop()
_future = loop.create_future()
await _future
asyncio.run(main())concurrent.futures.Future对象
使用线程池/进程池实现异步操作时用到的对象
import time
from concurrent.futures import Future
from concurrent.futures.thread import ThreadPoolExecutor
def func(value):
time.sleep(1)
print(value)
return 123
pool = ThreadPoolExecutory(max_workers=5)
for i in range(5)
fut = pool.submit(func,1)
print(fut)